Back in the day, I was myself saved from a career in complexity by Omer Reingold's logspace connectivity.
Friday, November 19, 2010
Complexity Theory
If you're a student thinking of going into complexity theory, take a good look around and ask yourself: "Do I really want to be in a field with this amount of groupthink?" [1,2,3,4,5, and last but certainly not least 6]
Wednesday, October 27, 2010
FOCS 2010
I am back from FOCS 2010, where I gave two talks:
- a tutorial on data structure lower bounds: PPSX, PDF
- a regular conference talk on distance oracles: PPSX, PDF (for this paper coauthored with Liam Roditty).
This paper caused some amount of fun in certain "inner circles", which I think I should share with a wider audience. If you read the paper, the algorithms repeatedly grow balls (aka shortest path trees) around vertices of the graph. After obsessing about growing these balls for more than a year, I found it natural to name the paper "How to Grow Your Balls". At least it allowed me to begin various talks by telling the audience that, "This is a topic of great economic importance; I receive email about it almost every day."
The committee took its role as Cerberus at the gates of Theory very seriously, and refused to accept the paper under the original title. In the process, many jokes were made, at least some of which transpired outside the PC room. I won't post them here, as the PC probably intends to keep some decorum. (But if you get a chance, ask your friend on the PC about that proposed proceedings cover.)
So the title changed, but I stretched the joke a bit further by titling the tutorial "How to Grow Your Lower Bounds".
This episode confirmed two things that I already knew. First, this community insists on taking itself way too seriously. For comparison, the title certainly triggered some PR alarms inside AT&T. But it made it through, perhaps because I told people that it's in the interest of AT&T Labs to prove publicly that it's a real research lab: it lets researchers be researchers, which includes being silly at times. Given the reputation of PR departments in American telecoms, it's a bit sad to find that the theory community has a higher bar on form.
Secondly, I should turn it down a notch with this blog. Several people said they had expected me to withdraw the paper rather than change the title. I found it quite amazing that people had such an image of me. Perhaps it is time to emphasize that I'm doing my research because I think it's important and cool. The horsing around is, well, not quite the main message.
Wednesday, September 29, 2010
Problem solving versus new techniques
This is a guest post by Mikkel Thorup:
--------------------------
I think there is nothing more inhibiting for problem solving than referees looking for new general techniques.
When I go to STOC/FOCS, I hope to see some nice solutions to important problems and some new general techniques. I am not interested in semi-new techniques for semi-important problems. A paper winning both categories is a wonderful but rare event.
Thus I propose a max-evaluation rather than a sum. If the strength of a paper is that it solves an important problem, then speculations on the generality of the approach are of secondary importance. Conversely, if the strength of the paper is some new general techniques, then I can forgive that it doesn't solve anything new and important.
One of the nice things about TCS is that we have problems that are important, not just as internal technical challenges, but because of their relation to computing. At the end of the day, we hope that our techniques will end up solving important problems.
Important problems should be solved whatever way comes natural. It may be deep problem specific understanding, and it may build on previous techniques. Why would we be disappointed if an old problem got solved by a surprising reuse of an old technique?
--------------------------
I think there is nothing more inhibiting for problem solving than referees looking for new general techniques.
When I go to STOC/FOCS, I hope to see some nice solutions to important problems and some new general techniques. I am not interested in semi-new techniques for semi-important problems. A paper winning both categories is a wonderful but rare event.
Thus I propose a max-evaluation rather than a sum. If the strength of a paper is that it solves an important problem, then speculations on the generality of the approach are of secondary importance. Conversely, if the strength of the paper is some new general techniques, then I can forgive that it doesn't solve anything new and important.
One of the nice things about TCS is that we have problems that are important, not just as internal technical challenges, but because of their relation to computing. At the end of the day, we hope that our techniques will end up solving important problems.
Important problems should be solved whatever way comes natural. It may be deep problem specific understanding, and it may build on previous techniques. Why would we be disappointed if an old problem got solved by a surprising reuse of an old technique?
Elegant reuse of old techniques is not a bad thing. After all, when we develop new techniques, we are hoping they will be reused, and from a teaching perspective, it is great to discover that the same general technique applies to more diverse problems. The last thing we want is to encourage authors to hide reuse. Of course, reuse should be highly non-obvious for a strong conference, but for established open problems, non-obviousness will normally be self-evident.
Monday, September 27, 2010
Retrieval-Only Dictionaries
We saw two cool applications of dictionaries without membership; now it's time to construct them. Remember that we are given a set S, where each element x∈S has some associated data[x], a k-bit value. We want a data structure of O(nk) bits which retrieves data[x] for any x∈S and may return garbage when queried for x∉S.
A conceptually simple solution is the "Bloomier filter" of [Chazelle, Kilian, Rubinfeld, Tal SODA'04]. This is based on the power of two choices, so you should first go back and review my old post giving an encoding analysis of cuckoo hashing.
Standard cuckoo hashing has two arrays A[1..2n], B[1..2n] storing keys, and places a key either at A[h(x)] or B[g(x)]. Instead of this, our arrays A and B will store k-bit values (O(nk) bits in total), and the query retrieve-data(x) will return A[h(x)] xor B[g(x)].
The question is whether we can set up the values in A and B such that any query x∈S returns data[x] correctly. This is a question about the feasibility of a linear system with n equations (one per key) and 4n variables (one per array entry).
Consider a connected component in the bipartite graph induced by cuckoo hashing. If this component is acyclic, we can fix A and B easily. Take an arbitrary node and make it "zero"; then explore the tree by DFS (or BFS). Each new node (an entry in A or B) has a forced value, since the edge advancing to it must return some data[x] and the parent node has been fixed already. As the component is acyclic, there is only one constraint on every new node, so there are no conflicts.
On the other hand, if a component has a cycle, we are out of luck. Remark that if we xor all cycle nodes by some Δ, the answers are unchanged, since the Δ's cancel out on each edge. So a cycle of length k must output k independent data values, but has only k-1 degrees of freedom.
Fortunately, one can prove the following about the cuckoo hashing graph:
- the graph is acyclic with some constant probability. Thus, the construction algorithm can rehash until it finds an acyclic graph, taking O(n) time in expectation.
- the total length of all cycles is O(lg n) with high probability. Thus we can make the graph acyclic by storing O(lg n) special elements in a stash. This gives construction time O(n) w.h.p., but the query algorithm is slightly more complicated (for instance, it can handle the stash by a small hash table on the side).
These statements fall out naturally from the encoding analysis of cuckoo hashing. A cycle of length k allows a saving of roughly k bits in the encoding: we can write the k keys on the cycle (klg n bits) plus the k hash codes (klg(2n) bits) instead of 2k hash codes (2klg(2n) bits).
Further remarks. Above, I ignored the space to store the hash functions h and g. You have to believe me that there exist families of hash functions representable in O(nε) space, which can be evaluated in constant time, and make cuckoo hashing work.
A very interesting goal is to obtain retrieval dictionaries with close to kn bits. As far as I know, the state of the art is given by [Pagh-Dietzfelbinger ICALP'08] and [Porat].
Tuesday, September 21, 2010
Static 1D Range Reporting
Method 4 for implementing van Emde Boas with linear space, described in my last post, is due to [Alstrup, Brodal, Rauhe: STOC'01]. They worked on static range reporting in 1 dimension: preprocess a set of integers S, and answer query(a,b) = report all points in S ∩ [a,b]. This is easier than predecessor search: you can first find the predecessor of a and then output points in order until you exceed b. Using van Emde Boas, we would achieve a linear-space data structure with query time O(lglg u + k), where k is the number of points to be reported.
Alstrup, Brodal, and Rauhe showed the following surprising result:
Static 1D range reporting can be solved with O(n) space and O(1+k) query time.
I like this theorem a lot, since it is so easy to describe to anybody with minimal background in Computer Science, yet the result is not obvious. I have used it many times to answer questions like, "Tell me a surprising recent result from data structures."
The solution. We need a way to find some (arbitrary) key from S ∩ [a,b] in constant time. Once we have that, we can walk left and right in an ordered list until we go outside the interval.
Let's first see how to do this with O(n lg u) space; this was described by [Miltersen, Nisan, Safra, Wigderson: STOC'95]. Of course, we build the trie representing the set. Given the query [a,b] let us look at the lowest common ancestor (LCA) of a and b. Note that LCA(a,b) is a simple mathematical function of the integers a and b, and can be computed in constant time. (The height of the LCA is the most significant set bit in a xor b.)
- if LCA(a,b) is a branching node, look at the two descendant branching nodes. If the interval [a,b] is nonempty, it must contain either the max in the tree of the left child, or the min in the tree of the right child.
- if LCA(a,b) is an active node, go to its lowest branching ancestor, and do something like the the above.
- if LCA(a,b) is not an active node, the interval [a,b] is certainly empty!
Thus, it suffices to find the lowest branching ancestor of LCA(a,b) assuming that LCA(a,b) is active. This is significantly easier than predecessor search, which needs the lowest branching ancestor of an arbitrary node.
The proposal of [Miltersen et al.] is to store all O(n lg u) active nodes in a hash table, with pointers to their lowest branching ancestors.
As in my last post, the technique of [Alstrup et al.] to achieve O(n) space is: store only O(n √lg u) active nodes, and store them in a retrieval-only dictionary with O(lglg u) bits per node. We store the following active nodes:
- active nodes at depth i·√lg u ;
- active nodes less than √lg u levels below a branching node.
We first look up LCA(a,b) in the dictionary. If the lowest branching ancestor is less than √lg u levels above, LCA(a,b) is in the dictionary and we find the ancestor. If not, we truncate the depth of the LCA to a multiple of √lg u , and look up the ancestor at that depth. If [a,b] is nonempty, that ancestor must be an active node and it will point us to a branching ancestor.
vEB Space: Method 4
In the previous post I described 3 ways of making the "van Emde Boas data structure" take linear space. I use quotes since there is no unique vEB structure, but rather a family of data structures inspired by the FOCS'75 paper of van Emde Boas. By the way, if you're curious who van Emde Boas is, here is a portrait found on his webpage.
{kind=link}
In this post, I will describe a 4th method. You'd be excused for asking what the point is, so let me quickly mention that this technique has a great application (1D range reporting, which I will discuss in another post) and it introduces a nice tools you should know.
Here is a particularly simple variant of vEB, introduced by Willard as the "y-fast tree". Remember from the last post that the trie representing the set has n-1 branching nodes connected by 2n-1 "active" paths; if we know the lowest branching ancestor of the query, we can find the predecessor in constant time. Willard's approach is to store a hash table with all O(n lg u) active nodes in the trie; for each node, we store a pointer to its lowest branching ancestor. Then, we can binary search for the height of the lowest active ancestor of the query, and follow a pointer to the lowest branching node above. As the trie height is O(lg u), this search takes O(lglg u) look-ups in the hash table.
Of course, we can reduce the space from O(n lg u) to O(n) by bucketing. But let's try something else. We could break the binary search into two phases:
- Find v, the lowest active ancestor of the query at some depth of the form i·√lg u (binary search on i). Say v is on the path u→w (where u, w are branching nodes). If w is not an ancestor of the query, return u.
- Otherwise, the lowest branching ancestor of the query is found at some depth in [ i·√lg u , (i+1)√lg u ]. Binary search to find the lowest active ancestor in this range, and follow a pointer to the lowest active ancestor.
With this modification, we only need to store O(n √lg u ) active nodes in the hash table! To support step 1., we need active nodes at depths i·√lg u. To support step 2., we need active nodes whose lowest branching ancestor is only ≤ √lg u levels above. All other active nodes can be ignored.
You could bring the space down to O(n lgεu) by breaking the search into more segments. But to bring the space down to linear, we use heavier machinery:
Retrieval-only dictionaries. Say we want a dictionary ("hash table") that stores a set of n keys from the universe [u], where each key has k bits of associated data. The dictionary supports two operations:
- membership: is x in the set?
- retrieval: assuming x is in the set, return data[x].
If we want to support both operations, the smallest space we can hope for is log(u choose n) + nk ≈ n(lg u + k) bits: the data structure needs to encode the set itself, and the data.
Somewhat counterintuitively, dictionaries that only support retrieval (without membership queries) are in fact useful. (The definition of such a dictionary is that retrieve(x) may return garbage if x is not in the set.)
Retrieval-only dictionaries can be implemented using only O(nk) bits. I will describe this in the next post, but I hope it is believable enough.
When is a retrieval-only dictionary helpful? When we can verify answers in some other way. Remember the data structure with space O(n √lg u ) from above. We will store branching nodes in a real hash table (there are only n-1 of them). But observe the following about the O(n √lg u ) active nodes that we store:
- We only need k=O(lglg u) bits of associated data. Instead of storing a pointer to the lowest branching ancestor, we can just store the height difference (a number between 1 and lg u). This is effectively a pointer: we can compute the branching ancestor by zeroing out so many bits of the node.
- We only need to store them in a retrieval-only dictionary. Say we query some node v and find a height difference δ to the lowest branching ancestor. We can verify whether v was real by looking up the δ-levels-up ancestor of v in the hash table of branching nodes, and checking that v lies on one of the two paths descending from this branching node.
Therefore, the dictionary of active nodes only requires O(n √lg u · lglg u) bits, which is o(n) words of space! This superlinear number of nodes take negligible space compared to the branching nodes.
Sunday, September 19, 2010
Van Emde Boas and its space complexity
In this post, I want to describe 3 neat and very different ways of making the space of the van Emde Boas (vEB) data structure linear. While this is not hard, it is subtle enough to confuse even seasoned researchers at times. In particular, it is the first bug I ever encountered in a class: Erik Demaine was teaching Advanced Data Structures at MIT in spring of 2003 (the first grad course I ever took!), and his solution for getting linear space was flawed.
Erik is the perfect example of how you can get astronomically high teaching grades while occasionally having bugs in your lectures. In fact, I sometimes suspected him of doing it on purpose: deliberately letting a bug slip by to make the course more interactive. Perhaps there is a lesson to be learned here.
***
Here is a quick review of vEB if you don't know it. Experienced readers can skip ahead.
The predecessor problem is to support a set S of |S|=n integers from the universe {1, ..., u} and answer:
The vEB data structure can answer queries in O(lglg u) time, which is significantly faster than binary search for moderate universes.predecessor(q) = max { x ∈ S | x ≤ q }
The first idea is to divide the universe into √u segments of size √u. Let hi(x) = ⌊x/√u⌋ be the segment containing x, and lo(x) = x mod √u be the location of x within its segment. The data structure has the following components:
- a hash table H storing hi(x) for all x ∈ S.
- a top structure solving predecessor search among { hi(x) | x ∈ S }. This is the same as the original data structure, i.e. use recursion.
- for each element α∈H, a recursive bottom structure solving predecessor search inside the α segment, i.e. among the keys { lo(x) | x ∈ S and hi(x)=α }.
The query algorithm first checks if hi(q) ∈ H. If so, all the action is in q's segment, so you recurse in the appropriate bottom structure. (You either find its predecessor there, or in the special case when q is less than the minimum in that segment, find the successor and follow a pointer in a doubly linked list.)
If q's segment is empty, all the action is at the segment level, and q's predecessor is the max in the preceding non-empty segment. So you recurse in the top structure.
In one step, the universe shrinks from u to √u, i.e. lg u shrinks to ½ lg u. Thus, in O(lglg u) steps the problem is solved.
***
So what is the space of this data structure? As described above, each key appears in the hash table, and in 2 recursive data structures. So the space per key obeys the recursion S(u) = 1 + 2 S(√u). Taking logs: S'(lg u) = 1 + 2 S'(½ lg u), so the space is O(lg u) per key.
How can we reduce this to space O(n)? Here are 3 very different ways:
Brutal bucketing. Group elements into buckets of O(lg u) consecutive elements. From each bucket, we insert the min into a vEB data structure. Once we find a predecessor in the vEB structure, we know the bucket where we must search for the real predecessor. We can use binary search inside the bucket, taking time O(lglg u). The space is (n/lg u) ·lg u = O(n).
Better analysis. In fact, the data structure from above does take O(n) space if you analyze it better! For each segment, we need to remember the max inside the segment in the hash table, since a query in the top structure must translate the segment number into the real predecessor. But then there's no point in putting the max in the bottom structure: once the query accesses the hash table, it can simply compare with the max in O(1) time. (If the query is higher than the max in its segment, the max is the predecessor.)
In other words, every key is stored recursively in just one data structure: either the top structure (for each segment max) or the bottom structure (for all other keys). This means there are O(lglg u) copies of each element, so space O(n lglg u).
But note that copies get geometrically cheaper! At the first level, keys are lg u bits. At the second level, they are only ½ lg u bits; etc. Thus, the cost per key, in bits, is a geometric series, which is bounded by O(lg u). In other words, the cost is only O(1) words per key. (You may ask: even if the cost of keys halves every time, what about the cost of pointers, counters, etc? The cost of a pointer is O(lg n) bits, and n ≤ u in any recursive data structure.)
Be slick. Here's a trickier variation due to Rasmus Pagh. Consider the trie representing the set of keys (a trie is a perfect binary tree of depth lg u in which each key is a root-to-leaf path). The subtree induced by the keys has n-1 branching nodes, connected by 2n-1 unbranching paths. It suffices to find the lowest branching node above the query. (If each branching node stores a pointer to his children, and the min and max values in its subtree, we can find the predecessor with constant work after knowing the lowest branching node.)
We can afford space O(1) per path. The data structure stores:
- a top structure, with all paths that begin and end above height ½ lg u.
- a hash table H with the nodes at depth ½ lg u of every path crossing this depth.
- for each α∈H, a bottom structure with all paths starting below depth ½ lg u which have α as prefix.
Observe that each path is stored in exactly one place, so the space is linear. But why can we query for the lowest branching node above some key? As the query proceeds, we keep a pointer p to the lowest branching node found so far. Initially p is the root. Here is the query algorithm:
- if p is below depth ½ lg u, recurse in the appropriate bottom structure. (We have no work to do on this level.)
- look in H for the node above the query at depth ½ lg u. If not found, recurse in the top structure. If found, let p be the bottom node of the path crossing depth ½ lg u which we just found in the hash table. Recurse to the appropriate bottom structure.
The main point is that a path is only relevant once, at the highest level of the recursion where the path crosses the middle line. At lower levels the path cannot be queried, since if you're on the path you already have a pointer to the node at the bottom of the path!
Tuesday, September 7, 2010
IOI Wrap-up
In the past 2 years, I have been a member of the Host Scientific Committee (HSC) of the IOI. This is the body that comes up with problems and test data. While it consists primarily of people from the host country (Bulgaria in 2009, Canada in 2010), typically the host will have a call-for-problems and invite the authors of problems they intend to use.
This year, I was elected member of the International Scientific Committee (ISC). This committee works together with the HSC on the scientific aspects, the hope being that a perenial body will maintain similar standards of quality from one year to another. There are 3 elected members in the ISC, each serving 3-year terms (one position is open each year).
I anticipate this will be a lot of fun, and you will probably hear more about the IOI during this time. When a call for problems comes up (will be advertised here), do consider submitting!
I will end with an unusual problem from this IOI:
My own approach was to define Score(text, language) as the minimal number of substrings seen previously in this language that compose the text. This can be computed efficiently by maintaining a suffix tree for each language, and using it to answer longest common prefix queries.
This year, I was elected member of the International Scientific Committee (ISC). This committee works together with the HSC on the scientific aspects, the hope being that a perenial body will maintain similar standards of quality from one year to another. There are 3 elected members in the ISC, each serving 3-year terms (one position is open each year).
I anticipate this will be a lot of fun, and you will probably hear more about the IOI during this time. When a call for problems comes up (will be advertised here), do consider submitting!
I will end with an unusual problem from this IOI:
Consider the largest 50 languages on Wikipedia. We picked 200 random articles in each language, and extracted an excerpt of 100 consecutive characters from each. You will receive these 10000 texts one at a time in random order, and for each you have to guess its language. After each guess, your algorithm learns the correct answer. The score is the percentage of correct guesses.Considering the tiny amount of training data and the real-time nature of guessing, one might not expect too good solutions. However, it turns out that one can get around 90% accuracy with relatively simple ideas.
To discourage students from coding a lot of special rules, a random permutation is applied to the Unicode alphabet, and the language IDs are random values. So, essentially, you start with zero knowledge.
My own approach was to define Score(text, language) as the minimal number of substrings seen previously in this language that compose the text. This can be computed efficiently by maintaining a suffix tree for each language, and using it to answer longest common prefix queries.
Sunday, August 29, 2010
Barriers 2
Later today, I'll be giving a talk at the 2nd Barriers Workshop in Princeton.
Update: Based on comments, I'm publishing the slides as PPSX (which can be viewed with a free viewer) and PDF. I will try to convert my other talks to these formats when I have time.
Thursday, August 26, 2010
IOI: A Medium Problem
Here is another, medium-level problem from the IOI. (Parental advisory: this is not quite as easy as it may sound!)
I think of a number between 1 and N. You want to guess the secret number by asking repeatedly about values in 1 to N. After your second guess, I will always reply "hotter" or "colder", indicating whether your recent guess was closer or farther from the secret compared to the previous one.
You have lg N + O(1) questions.
***
The solution to the first problem I mentioned can be found in the comments. Bill Hesse solved the open question that I had posed. He has a neat example showing that the space should be N1.5log23 bits, up to lower order terms. It is very nice to know the answer.
A very elegant solution to the second problem was posted in the comments by a user named Radu (do you want to disclose your last name?). Indeed, this is simpler than the one I had. However, the one I had worked even when the numbers in the array were arbitrary (i.e. you could not afford to sort them in linear time). I plan to post it soon if commenters don't find it.
Sunday, August 22, 2010
IOI: Another Hard Problem
You are given a matrix A[1..N][1..M] that contains a permutation of the numbers {1, ..., NM}. You are also given W≤N and H≤M. The goal is to find that rectangle A[i ... i+W][j ... j+H] which has the lowest possible median.
Running time: O(NM).
***
This could have been another hard problem at the IOI, but it was decided to give maximum score to solutions running in O(NM lg(NM)). This is considerably easier to obtain (but still interesting).
In the style of what Terry Tao tried for the IMO, I am opening this blog post as a discussion thread to try to solve the problem collectively ("poly-CS" ?). You are encouraged to post any suggestions, half-baked ideas, trivial observations, etc – with the goal to jointly reach a solution. If you think about the problem individually and find the solution, please don't post, as it will ruin the fun of the collective effort. Following this rule, I will not engage in the discussion myself.
I did not encourage a discussion for the first problem, since it was the kind of problem that only required one critical observation to solve. This second problem requires several ideas, and in fact I can see two very different solutions.
Friday, August 20, 2010
IOI: The Hard Problem
The International Olympiad in Informatics (IOI 2010) is taking part this week at the University of Waterloo, Canada.
The olympiad often features a hard problem, which is intended to be solved by a handful of contestants. This year, the problem was solved by about 6 people. Read the problem below and give it a shot! :)
I will describe the problem in both TCS and IOI fashion.
Asymptotic version. You are given an unweighted, undirected graph on N vertices. Some sqrt(N) vertices are designated as "hubs". You have to encode the pairwise distances between all hubs and all vertices in O(N1.5) bits of space.
The encoder and decoder may run in polynomial time. Of course, the decoder does not see the original graph; it receives the output of the encoder and must output the explicit distances between any hub and any other vertex. (This list of explicit distances takes O(N1.5lg N) bits.)
Non-asymptotic version. You are given a graph on 1000 nodes and 36 designated hubs. You have to encode the distances between all hubs and all vertices in 70,000 bits of space.
The non-asymptotic version is a bit harder, since you have to pay more attention to some details.
The research version. Prove or disprove that the distances can be encoded using (1+o(1)) N1.5 bits of space. I don't know the answer to this question (but I find the question intriguing.)
Wednesday, August 4, 2010
A taxonomy of range query problems
In this post, I will try to enumerate the range query problems that I know about. Let me know if I'm missing anything.
The query. Say you have n points in the plane, and you query for the points in an axis-parallel rectangle. What could we mean by "query"?
- existential range queries: Is there any point in the rectangle?
- counting queries: How many points are there in the rectangle?
- reporting queries: List the points in the rectangle. Unlike the previous cases, the query time is now broken into two components: it is usually given as f(n) + k*g(n), where k is the number of output points.
Now let's assume the points have some number associated to them (a weight or a priority). Then one could ask the following natural queries:
- weighted counting: What is the total weight of the points inside?
- range min (max) query
- range median query. (Possible generalizations: selection or quantiles.)
- top-k reporting: Report just the top k guys, by priority (for k given). One may demand the output to be sorted. More stringently, one may ask the query algorithm to enumerate points sorted by priority, in time g(n) per point, until the user says "stop."
The number associated to a point can also be a "color". For instance, points could represent Irish pubs / Belgian bars / etc, and we may only want one point of each type in our output. Then the queries become:
- colored counting: How many distinct colors are in the rectangle?
- colored reporting: List the distinct colors in the rectangle (possibly with one example point from each color).
- top-k colored reporting: If the colors are sorted by priorities (e.g. I prefer points of color 1 over points of color 2), one can then ask for the top-k distinct colors inside the rectangle.
Dynamism. The problem could be:
- static: Preprocess the point set and then answer queries.
- dynamic: Insert and delete from the point set.
- incremental / decremental: We only insert or delete.
- offline: The sequence of operations is known in advance. This is enough for many applications to algorithms.
- parametric / kinetic. I confess ignorance with respect to these.
Orthogonal range queries. The setting from above works in any number of dimensions d≥1: the data set consists of n points in d-dimensional space and the query is a box [a1, b1]×···×[ad, bd]. This setup is usually called "orthogonal range queries".
We can consider the following important restrictions on the query:
- dominance queries: the box is [0, b1]×···×[0, bd]. In other words, we are asking for the points dominated, coordinate-wise, by a point (b1, ..., bd).
- k-sided queries: exactly 2d-k values in (a1, a2, ..., ad) are zero. For instance, a 3-sided query in 2D is a rectangle with one side on the x axis. Dominance queries are the special case of d-sided queries.
The universe. The coordinates of the points and queries can come from the following sets:
- general universe. In the standard RAM model, we assume that the coordinates are integers that fit in a machine word.
- rank space: the coordinates are from {1, 2, ..., n}. One can reduce any static problem to rank space by running 2d predecessor queries. Most problems can be shown to be at least as hard as predecessor search, so their complexity is precisely: "optimal cost of predecessor search" + "optimal cost for the problem in rank space". In other words, for most problems it is sufficient to solve them in rank space.
- dense universe: the points are exactly the points of the grid [1, n1]×···×[1, nd] where n1n2···nd = n. In 1D this is the same as rank space, but in 2 or more dimensions the problems are very different. (To my knowledgeable readers: Is there a standard name for this case? For counting queries people call this "the partial sums problem", but how about e.g. min queries?)
For dynamic problems, the "rank space" changes when a new coordinate value is inserted. Thus, a rank-space solution must support a "insert value" operation that increments all coordinate values after a given one, creating space for a newly inserted point. (I have heard the term "list space" for this. Should we just use "rank space"?)
Stabbing. So far, our data set consisted of points and the queries asked for points in a given rectangle. Conversely, one can consider a data set of rectangles; the query is a point and asks about the rectangles containing that point ("stabbed" by it). This problem is important, among others, in routing: we can have rules for packets coming from some range of IP addresses and going to some other range of IP addresses.
The notion of rank space, and all query combinations still make sense. For instance, interval max stabbing is the following problem: given a set of interval (in 1D) with priorities, return the interval of highest priority stabbed by a query point.
Note that the rectangles in the input can intersect! If we ask that the rectangles be disjoint, or more stringently, be a partition of the space, we obtain the point location problem.
Rectangle-rectangle queries. So far we looked at containment relations between rectangles and points. More generally, the data set can consist of rectangles, and the query can also be a rectangle. Then one can ask:
- intersection queries: analyze the set of input rectangles that intersect the query rectangle.
- containment queries: analyze the set of rectangles that contain / are-contained-by the query.
Two important special cases arise when the rectangles degenerate to line segments:
- orthogonal segment intersection: Given a set of horizontal segments, find the ones that intersect a vertical query segment.
- orthogonal ray shooting: Given a set of horizontal segments, find the lowest one immediately above a query point. In other words, consider a vertical ray leaving from the point and find the first segment it intersects. (This is the min segment intersection query, where the priority of each horizontal segment is its y coordinate.)
More complex geometry. Of course, our ranges need not be orthogonal. One can consider:
- balls
- arbitrary lines
- half spaces
- simplices (e.g 2D triangles).
In non-orthogonal geometry, the concept of rank space disappears. However, most other combinations are possible. For instance, one could ask about the points in a query range; the ranges stabbed by a query point; the ranges intersecting a query range; the first rangeintersected by a ray; etc. We can ask existential, counting, or reporting questions, on ranges that can have weights or priorities.
Thursday, July 22, 2010
SODA
Being on the SODA PC is excruciating. Too many submissions are at the level of a hard exercise – things that David Karger would assign in Advanced Algorithms or Randomized Algorithms as homework. And since I'm a problem solver by nature, I cannot resist solving the problems before (in lieu of) reading the papers...
I am left wondering how life on the ICS PC is like. The fact that the PC members can solve the problem in half an hour is promised to not be a negative – so is there any point in engaging the technical side of your brain during the review process?
Which brings me to graph algorithms, a field I have engaged in sporadically. This field strikes me as problem solving par excellence. You think about the problem, you pull a rabbit out of the hat, and run around naked screaming "Εὕρηκα!" Yet most reviewers (which, I will assume, write graph-theory papers in the same way) cannot help commenting on the lack of new techniques in the solution. I interpret this as a code for "We didn't care to think about the problem, we just read over your solution and remarked that it solved the problem by looking at some edges in some order, then at some trees and some vertices."
(I should say I have no sour grapes about this... Graph algorithms in not my main field and all my papers on the topic are in STOC/FOCS. Yet I am amazed by how much the field sabotages itself with this "techniques thing.")
By contrast, I once came across a reviewer that actually wore his problem-solver hat while reading my paper. The review read "I spent days to figure out the interplay and indispensability of the data structures and techniques used. But after fully understanding the entire picture and the interplay of all the data structures, I felt very satisfied. It is indeed a very beautiful piece of algorithmic art. I congratulate the authors for such a novel algorithm." This is possibly the best review I ever got – complemented, of course, by some "no new techniques but important result" reviews.
Which brings me to the main trouble with TCS, in my opinion. If only we could stop inventing a ton of artificial problems every year, and we actually cared about solving some age-old clear-cut problems – then it would be no surprise to find reviewers that have actually thought carefully about your hard problem.
Monday, June 21, 2010
3SUM Puzzle
A puzzle courtesy of Mohan Paturi:
Given a set S of n numbers, the 3SUM problem asks whether there exist a,b,c ∈ S such that a+b+c=0. It is generally believed that this should take around n2 time.
But let's assume |S+S| = t ≪ n2. Show that the problem can be solved in O(t lg2n) time.
Any ideas for a better bound?
Wednesday, June 9, 2010
Journals
There is a fraction of our community who is in love with the idea of publishing in journals, and would like to see our conferences go away or assume a radically different role. In many of the cases, it seems to me that the driving force behind this idea is nothing more than snobbery. Basically, the argument goes like this: (1) I think Mathematicians are cool; (2) Mathematicians publish in journals.
If one is willing to admit that a field can persist in stupidy for a long time due to tradition, then one has to also entertain the possibility that Computer Science is the grown-up in the house, while Mathematics is stuck with remnants of an era when travel was hard, and presenting the graduate students to a welcoming community was not considered important.
But it's not possible to poke fun at journals without the pedantic person in the room jumping up and down that conference publications are not formally verified. This view is, in my opinion, entirely deserving of a counterpoint to Lance's essay entitled "Time for Theoretical Computer Scientists to Stop Believing Fairy Tales".
There are basically two reasons to believe a paper is correct, none of which is that some bored editor used up some brownie points with a friend, who(se student) gave the paper a quick read while watching a World Cup game:
- The authors thought seriously about it and wrote down all the details. Regardless of what you think about journals, this should already be achieved at conference level. Yes, a conference is an announcement -- but I care when you announce "I've done this!" rather than "I'm reasonably sure I can do this." It is beyond my comprehension why conferences do not require full proofs (despite several successful attempts in the past).
- Interested people read it. Yesterday, Timothy Chan sent me a breakthrough paper. Between giving two talks, kayaking on the Charles, and driving back from STOC, I really couldn't read it. But today I read it, and flipped it upside down in my mind until I got it. The value of putting such a paper in a journal? (cdr '(a))
If you tend to write readerless publications, abolishing the journal system might create a distinct feeling of loneliness, as you can't even be sure that you have a few constrained readers. My heart bleeds for you.
But if/when people are interested in your paper, it will be checked for correctness. I've been impressed many times by how well this works, and by the dedication reviewers put in during the short time frame of conference review. Many bugs get caught at the STOC/FOCS level --- by people who care. And if a bug is not caught in time, there's no loss: it will be caught when the paper becomes interesting. (One could certainly imagine improvements to the system, like a requirement that all papers be on arXiv with requests for clarifications/bug reports/discussions posted below the fold. But that's a different crusade.)
To summarize, the journal vs. conference debate is an easy cosmetic change that we can pursue to feel like we're changing something, but it's besides the point if correctness is what we want. We should instead be tackling the real issue: how to increase the quality and readership of our papers. Can we reduce the (perceived) expectation on the number of papers one should publish? Fight the Least Publishable Unit philosophy? Achieve more unity in the field? Reduce the number of conferences, while also allowing smaller results to appear (posters anyone?)...
Funny enough, this is well aligned with another hot goal of the day: increasing conference participation. If papers have more readers and people don't need to travel to the Kingdom of Far Far Away to publish uninteresting papers, there are probably more people showing up at STOC/FOCS/SODA.
Wednesday, June 2, 2010
Representing a vector
This is the second post about "Changing Base without Losing Space." The main result of the paper is, if I am allowed to say it, rather amazing:
On a binary computer, you can represent a vector of N decimal digits using ⌈N·log210⌉ bits, and support reading/writing any digit in constant time.Of course, this works for any alphabet Σ; decimal digits are just an example.
Unlike the prefix-free coding from last time, this may never find a practical application. However, one can hardly imagine a more fundamental problem than representing a vector on a binary computer --- this statement that could have been discovered in 1950 or in 2050 :) Somebody characterized our paper as "required reading for computer scientists." (In fact, if you teach Math-for-CS courses, I would certainly encourage you to teach this kind of result for its entertainment value.)
To understand the solution, let's think back of the table for prefix-free coding from last time:
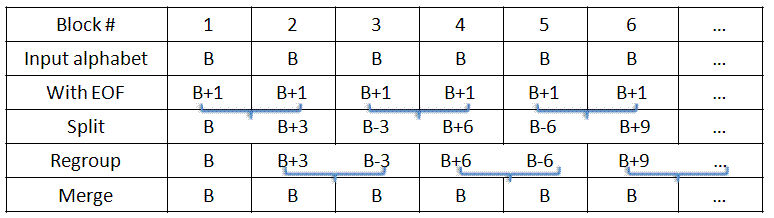
- I have two symbols from alphabet B+1. I need an output alphabet of B, so let's split them into a letter from B, and whatever is left (in particular, a letter from B+3).
- I have a letter from B+3. Can I combine it with another letter to make something close to a power of 2? Yes, I should use a letter from alphabet B-3, since (B+3)(B-3) is close to B2.
- How can I get a letter from B-3? Take the next two input symbols, and split them into a letter from B-3, and whatever is left (in particular, a letter from B+6).

If I want to output M bits (M≫lg X), I have to combine the symbol from X with a symbol from Y=⌊2M/X⌋. The loss of entropy will be lg(Y+1) - lg Y = O(1/Y), since the floor function could convert Y+0.9999 into Y.
Now I have to get a symbol from Y. This is possible if my information carrier came from some alphabet T≫Y. Then, I can break it into a symbol from Y, and one from Z=⌈T/Y⌉. Again, the entropy loss is lg Z - lg(Z-1)=O(1/Z), since the ceiling can convert Z-0.9999 into Z.
To balance the losses, set Y≈Z≈√T. That is, by having a large enough information carrier, I can make the loss negligible. In particular, if I apply the information carrier N times, I could set T≈N2, meaning that I only lose O(1/N) bits per application, and only a fraction of a bit overall! (This fraction of a bit will become one entire bit at the end, since I need to write the last symbol in binary.)
Thus, in principle, I could encode an array of digits by grouping them into blocks of O(lg N) digits (making T=the alphabet of a block be large enough). Then, I can iteratively use one block as the information carrier for the leftover of the previous block (the Z value from the previous block). The crucial observation is that, to decode block i, we only need to look at memory locations i (giving the Y component) and i+1 (giving the Z component). Thus, we have constant time access!
The one questionable feature of this scheme is that it requires O(N) precomputed constants, which is cheating. Indeed, the alphabets Y and Z change chaotically from one iteration to the next (the next Y is dictated by the previous Z, "filling it" to a power of two). There seems to be no pattern to these values, so I actually need to store them.
One can get away with just O(lg N) constants by applying the information carrier idea in a tree fashion. The alphabets will vary from level to level, but are identical on one level by symmetry. See the paper for complete details.
I will talk about my second STOC paper ("Towards Polynomial Lower Bounds for Dynamic Problems") after the conference.
Prefix-Free Codes
I am told the least this blog could do is to talk about my own results :) So here goes.
Next week at STOC, I am presenting "Changing Base without Losing Space," a joint paper with Mikkel Thorup and Yevgeniy Dodis. The paper and slides can be found here. The paper contains two results achieved by the same technique. Today, I will talk about the simpler one: online prefix-free codes.
The problem is to encode a vector of bits of variable length in a prefix-free way; that is, the decoder should be able to tell when the code ends. (Note on terminology: In information theory, this is called "universal coding"; prefix-free is about coding letters from a fixed alphabet, e.g. the Hamming code is prefix-free.)
Let N be the (variable) length of the bit vector. Here are some classic solutions (known as Elias codes):
- A code of 2N bits: after each data bit, append one bit that is 0 for end-of-file (EOF) or 1 if more data is coming;
- A code of N+2lg N bits: at the beginning of the message, write N by code 1; then write the bit vector.
- A code of N+lg N+2lglg N bits: at the beginning, write N by code 2; then write the bit vector.
- Recursing, one obtains the optimal size of N+lg N+lglg N+...+O(lg*N)

However, this is only secure if the input is prefix-free, or otherwise we are vulnerable to extension attacks:

This creates the need for online prefix-free codes: I want to encode a stream of data (in real time, with little buffering), whose length is unknown in advance. In this setting, the simplest solution using 2N bits still works, but the others don't, since they need to write N at the beginning. In fact, one can "rebalance" the 2N solution into an online code of size N+O(√N): append a bit after each block of size √N, wasting a partially-filled block at the end. Many people (ourselves included) believed this to be optimal for quite some time...
However, our paper presents an online code with ideal parameters: the size is N+lg N+O(lglg N), the memory is only O(lg N), and the encoding is real time (constant time per symbol). Since the solution is simple and practical, there is even reason to hope that it will become canonical in future standards!
So, how do we do it? I will describe the simplest version, which assumes the input comes in blocks of b bits and that b≫2lg N (quite reasonable for b=128 as in AES). Each block is a symbol from an alphabet of size B=2b. We can augment this alphabet with an EOF symbol; in principle, this should not cost much, since lg(B+1)≈lg B for large B. More precisely, N symbols from an alphabet of B+1 have entropy N·lg(B+1) = N·b+O(N/B) bits, so there's negligible loss if B≥N.
The problem, though, is to "change base without losing space": how can we change from base B+1 (not a power of two) into bits in real time? A picture is worth 1000 words:
We can think of two continuously running processes that regroup two symbols into two symbols of different alphabets:
- Split: Two input symbols in alphabet B+1 are changed into two symbols in alphabets B-3i and B+3(i+1), for i=0,1,2,... This works as long as (B-3i)(B+3i+3) ≥ (B+1)2, which is always the case for n2 ≤ B/4 (hence the assumption b≫2lg N).
- Merge: Two input symbols in alphabet B-3i and B+3i are regrouped into two symbols in alphabet B, which can be written out in binary (b bits each). This is always possible, since (B-3i)(B+3i) ≤ B2
Tuesday, June 1, 2010
MADALGO summer school
MADALGO is organizing a Summer School on Geometric Data Structures on Aug 16-19 in Aarhus, Denmark. Registration and local food are free (with a capacity limit), but you have to get there on your own dime.
The speakers are Timothy Chan, Sariel Har-Peled, John Iacono, and yours truly. We will strive to make this a very instructive event, and I would encourage you to attend.
Avner Magen
On May 29, Avner died in an avalanche while climbing in Alaska. A memorial blog has been set up here.
Like research, climbing is about fighting the soul-less nature. A mountain peak or a proof take no pity on our attempts --- they are as hard to reach as they have been since time immemorial. When we succeed to reach the top, our flesh and soul are the mark of our superiority, for we can feel a joy that nature does not share. But when we fail, our flesh and soul are our sorrow.
Rest in peace, Avner. Researchers and climbers have enjoyed your company.
Friday, February 12, 2010
The 6 Months News Cycle
The STOC accepted papers, with some pointers to online versions, can be found here. I had two papers: Towards Polynomial Lower Bounds for Dynamic Problems and Changing Base without Losing Space. More on them later.
The FOCS call for papers is here. An experimental feature is the lack of page limits. While nominally the reviewers are only obliged to look at the first 10 pages, we all know such formalism is irrelevant. Reviewers look at anywhere between 0.5 and 50 pages, until they form some opinion about the paper. As an author, I'm happy to stop playing the childish \baselinestretch and \appendix games, which were not helping anyone.
On the other hand, I vividly remember a discussion during my tenure on the FOCS PC when people made a strong case for a strict 10-page submission limit (no appendix). Many authors don't give a damn about teaching the reader anything, and seem driven by the desire to make their paper look as long and technical as possible. The reasoning was that a strict 10-page limit might actually force them to explain some ideas. Instead of a strict page limit, I would actually advocate using reviewers that are not easily intimidated, and stop accepting papers just because "it looks hard and these people seem to have put a lot of effort into it." In practice, of course, this ideal is hard to implement.
Forward by one conference, and I am on the SODA PC. This seems to be a standard punishment for having 4 papers in the conference. Speaking of which, I have recently uploaded slides for all these papers.
I am travelling to Europe in the coming weeks, so my series on hashing will continue at a slower pace.
Tuesday, February 2, 2010
Cuckoo Hashing
Today, we will prove bounds for the basic cuckoo hashing. We are going to place our n keys into two arrays A[1..b] and B[1..b], where b=2n. For this, we will use two hash functions, h and g. When some element x arrives, we first try to put it in A[h(x)]. If that location already contains some element y, try to move y to B[g(y)]. If that location already contains some z, try to move z to A[h(z)], and so on until you find a free spot.
The proper image to have in mind is that of a random bipartite graph. The graph will have b nodes on each side, corresponding to the locations of A and B. In this view, a key x is an edge from the left vertex h(x) to the right vertex g(x).
Simple paths. As a warm-up, let's deal with the case of simple paths: upon inserting x, the update path finds an empty spot without intersecting itself. It turns out that the update time of cuckoo hashing behaves like a geometric random variable:
In our case, E={insert(x) traverses a simple path of length k} and we will achieve a saving of Δ=Ω(k). Here is what we put in the encoding:
The intuition for why a k-path occurs with probability 2-Ω(k) is simple. Say I've reached edge y and I'm on the right side. Then, the probability that B[g(y)] is collision free is at least 1/2, since there are only n keys mapped to a space of 2n. In other words, at each point the path stops with probability half. This is exactly what the encoding is saying: we can save one bit per edge, since it takes lgn to encode an edge, but lg(2n) to encode an endpoint.
One cycle. Let us now deal with the case that the connected component of x contains one cycle. It is tempting to say that cuckoo hashing fails in this case, but it does not. Here is what might happen to the update path in case a cycle is part of the component (see figure):
 As before, we want to show that an update takes time k with probability 2-Ω(k). In cases 1 and 2, we can simply apply the encoding from before, since the path is simple. In case 3, let ℓ be the number of edges until the path meets itself. The number of edges after B[g(x)] is at least k-2ℓ. Thus, we have a simple path from x of length max{ℓ, k-2ℓ} = Ω(k), so the old argument applies.
As before, we want to show that an update takes time k with probability 2-Ω(k). In cases 1 and 2, we can simply apply the encoding from before, since the path is simple. In case 3, let ℓ be the number of edges until the path meets itself. The number of edges after B[g(x)] is at least k-2ℓ. Thus, we have a simple path from x of length max{ℓ, k-2ℓ} = Ω(k), so the old argument applies.
Two cycles. We now arrive at the cases when cuckoo hashing really fails: the bipartite graph contains as a subgraph (1) a cycles with a chord; or (2) two cycles connected by a path (possibly a trivial path, i.e. the cycles simply share a vertex).
 From the figure we see that, by removing two edges, we can always turn the bad subgraph into two paths starting at x. We first encode those two paths as above, saving Ω(k), where k=size of the subgraph. Now we can add to the encoding the two infringing edges. For each, we can specify its identity with lg n bits, and its two end points with O(lg k) bits (a lower order loss compared to
From the figure we see that, by removing two edges, we can always turn the bad subgraph into two paths starting at x. We first encode those two paths as above, saving Ω(k), where k=size of the subgraph. Now we can add to the encoding the two infringing edges. For each, we can specify its identity with lg n bits, and its two end points with O(lg k) bits (a lower order loss compared to
the Ω(k) saving). In return, we know their two hash codes, which are worth 4lg b bits. Thus, the overall saving is at least 2lg n bits.
We have shown that an insertion fails with probability O(1/n2). By a union bound, cuckoo hashing will handle any fixed set of n elements with probability 1-O(1/n).
This bound is actually tight. Indeed, if three keys x,y,z have h(x)=h(y)=h(z) and g(x)=g(y)=g(z), then cuckoo hashing fails (this is the simplest obstruction subgraph). But such a bad event happens with probability (n choose 3)·b2 / b6 = Θ(1/n).
The proper image to have in mind is that of a random bipartite graph. The graph will have b nodes on each side, corresponding to the locations of A and B. In this view, a key x is an edge from the left vertex h(x) to the right vertex g(x).
Simple paths. As a warm-up, let's deal with the case of simple paths: upon inserting x, the update path finds an empty spot without intersecting itself. It turns out that the update time of cuckoo hashing behaves like a geometric random variable:
The probability that insert(x) traverses a simple path of length k is 2-Ω(k).I will prove this by a cute encoding analysis (you know I like encoding proofs). Let's say you want to encode the two hash codes for each of the n keys. As the hash functions h and g are truly random, this requires H=2nlg b bits on average (the entropy). But what if, whenever some event E happened, I could encode the hash codes using H-Δ bits? This would prove that Pr[E]=O(2-Δ): there are only O(2H-Δ) bad outcomes that lead to event E, out of 2H possible ones. Thus, the task of proving a probability upper bound becomes the task of designing an algorithm.
In our case, E={insert(x) traverses a simple path of length k} and we will achieve a saving of Δ=Ω(k). Here is what we put in the encoding:
- one bit, saying whether the path grows from A[h(x)] or B[g(x)];
- the value k, taking O(lg k) bits;
- all edges of the path, in order, taking (k-1)lg n bits.
- all vertices of the path, in order, taking (k+1)lg b bits.
- the hash codes for all keys not on the path, in order, taking (n-k)·2lg b bits.
The intuition for why a k-path occurs with probability 2-Ω(k) is simple. Say I've reached edge y and I'm on the right side. Then, the probability that B[g(y)] is collision free is at least 1/2, since there are only n keys mapped to a space of 2n. In other words, at each point the path stops with probability half. This is exactly what the encoding is saying: we can save one bit per edge, since it takes lgn to encode an edge, but lg(2n) to encode an endpoint.
One cycle. Let us now deal with the case that the connected component of x contains one cycle. It is tempting to say that cuckoo hashing fails in this case, but it does not. Here is what might happen to the update path in case a cycle is part of the component (see figure):
- the path luckily avoids the cycle and finds a free location without intersection itself. Cool.
- the path reaches B[g(x)], which is occupied by some key y. Note that this has closed the cycle through the x edge, but the x edge is not actually traversed. Following y to A[h(y)] must eventually reach a free spot (no more cycles).
- the path intersects itself. Then, it will start backtracking, flipping elements back to their position before Insert(x). Eventually, it reaches A[h(x)], where the algorithm had originally placed x. Following the normal cuckoo rules, x is moved to B[g(x)] and the exploration from there on must find an empty spot.
 As before, we want to show that an update takes time k with probability 2-Ω(k). In cases 1 and 2, we can simply apply the encoding from before, since the path is simple. In case 3, let ℓ be the number of edges until the path meets itself. The number of edges after B[g(x)] is at least k-2ℓ. Thus, we have a simple path from x of length max{ℓ, k-2ℓ} = Ω(k), so the old argument applies.
As before, we want to show that an update takes time k with probability 2-Ω(k). In cases 1 and 2, we can simply apply the encoding from before, since the path is simple. In case 3, let ℓ be the number of edges until the path meets itself. The number of edges after B[g(x)] is at least k-2ℓ. Thus, we have a simple path from x of length max{ℓ, k-2ℓ} = Ω(k), so the old argument applies.Two cycles. We now arrive at the cases when cuckoo hashing really fails: the bipartite graph contains as a subgraph (1) a cycles with a chord; or (2) two cycles connected by a path (possibly a trivial path, i.e. the cycles simply share a vertex).
 From the figure we see that, by removing two edges, we can always turn the bad subgraph into two paths starting at x. We first encode those two paths as above, saving Ω(k), where k=size of the subgraph. Now we can add to the encoding the two infringing edges. For each, we can specify its identity with lg n bits, and its two end points with O(lg k) bits (a lower order loss compared to
From the figure we see that, by removing two edges, we can always turn the bad subgraph into two paths starting at x. We first encode those two paths as above, saving Ω(k), where k=size of the subgraph. Now we can add to the encoding the two infringing edges. For each, we can specify its identity with lg n bits, and its two end points with O(lg k) bits (a lower order loss compared tothe Ω(k) saving). In return, we know their two hash codes, which are worth 4lg b bits. Thus, the overall saving is at least 2lg n bits.
We have shown that an insertion fails with probability O(1/n2). By a union bound, cuckoo hashing will handle any fixed set of n elements with probability 1-O(1/n).
This bound is actually tight. Indeed, if three keys x,y,z have h(x)=h(y)=h(z) and g(x)=g(y)=g(z), then cuckoo hashing fails (this is the simplest obstruction subgraph). But such a bad event happens with probability (n choose 3)·b2 / b6 = Θ(1/n).
Better Guarantees for Chaining and Linear Probing
Last time we showed that chaining and linear probing enjoy O(1) expected running times per operation. However, this guarantee is fairly weak, and certainly does not explain the popularity of the schemes. If you had a computation that was expected to run for 4 hours, would you be happy to hear, say, that it might take 10 hours with 10% probability?
Worst case w.h.p. So, what bound can be put on the running time that hold with high probability? For chaining, simply apply the Chernoff bound. Given that a bin contains μ=O(1) elements in expectation, the probability that it contain Z elements is at most eZ-μ / (μ/Z)Z = (O(1)/Z)Z. To make this be n-c, set Z=Θ(lg n/lglg n).
Observe that this bound is tight. There are (n choose Z) ≈ nZ/Z! combinations of keys that can land in a designated bin, and some Z keys land there with probability b-Z=(2n)-Z. Thus, in expectation, at least one bin will see Z=Ω(lg n/lglg n) elements.
For linear probing, we can also reduce this to a balls-in-bins analysis, by defining a bin as L=O(lg n) consecutive locations in the array. In the running example b=2n, such a bin is full when Z=2μ=L. By Chernoff, this happens with probability eZ-μ / (μ/Z)Z = (e/4)L/2. Thus, the maximal run in O(lg n) w.h.p. Again, this is tight by a direct calculation.
Amortized bounds. Unfortunately, these worst-case1 bounds are not too satisfactory either, since O(lg n) is trivial to get by binary trees. If you grant me some lenience for my modeling, I will prove an O(1) amortized bound w.h.p., which I believe explains the power of the algorithms much better.
But does this actually mean that chaining has O(1) amortized running time? Formally, no: if I repeat a single query T times, the running time will be T times the running time of that query, i.e. a geometric random variable with no good concentration. Here is where I invoke a bit of lenience in my modeling: in practice, it is ridiculous to worry about repeating one of the last O(lg n) operations! The memory used by these recent updates will be fresh in the first level of cache, making a repetition cost essentially zero. (One may formally say that chaining has amortized O(1) running time w.h.p. in the external memory model with a cache of size Ω(lg n).)
A pretty way to understand the amortized bound is as a "buffer size" guarantee. The most demanding applications of hashtables are in analyzing a continuous stream of data, when operations need to be super-fast to keep up with the line speed. In such application, if the design is at all sensible, there will be a buffer between the network interface and our CPU. The goal is not necessarily to take O(1) time for every single operation, but to keep the buffer small. Our proof says that the buffer will not grow to more than T=O(lg n) w.h.p., if you can afford the average time/operation.
For linear probing, we can instead show:
Let μ be the number of keys we expect under some node. First of all, if μ≫lg n, we do not need to worry about the node: it doesn't become dangerous w.h.p. Otherwise, we showed that the node becomes dangerous with probability O(1/μ2); if it does, we will pay a cost of μ.
Looking at T elements, I am dealing with ≤T nodes on each level, and I expect O(T/μ2) nodes to be dangerous. As long as T/μ2 ≥ clg n, Chernoff tells me that only O(T/μ2) nodes are dangerous w.h.p. Since we only deal with μ=O(lg n), I needed to set T=Ω(lg3n). With this bound, the number of memory locations accessed by the T operations is Σμ=2^i O(T/μ2)·μ = O(T) w.h.p.
I end with a question to my knowledgeable readers. By being more careful, I can prove T=Ω(lg1+εn) suffices for linear probing. Is it possible to prove T=Ω(lg n), as in chaining? (Perhaps I'm missing something obvious.)
Worst case w.h.p. So, what bound can be put on the running time that hold with high probability? For chaining, simply apply the Chernoff bound. Given that a bin contains μ=O(1) elements in expectation, the probability that it contain Z elements is at most eZ-μ / (μ/Z)Z = (O(1)/Z)Z. To make this be n-c, set Z=Θ(lg n/lglg n).
Observe that this bound is tight. There are (n choose Z) ≈ nZ/Z! combinations of keys that can land in a designated bin, and some Z keys land there with probability b-Z=(2n)-Z. Thus, in expectation, at least one bin will see Z=Ω(lg n/lglg n) elements.
For linear probing, we can also reduce this to a balls-in-bins analysis, by defining a bin as L=O(lg n) consecutive locations in the array. In the running example b=2n, such a bin is full when Z=2μ=L. By Chernoff, this happens with probability eZ-μ / (μ/Z)Z = (e/4)L/2. Thus, the maximal run in O(lg n) w.h.p. Again, this is tight by a direct calculation.
Amortized bounds. Unfortunately, these worst-case1 bounds are not too satisfactory either, since O(lg n) is trivial to get by binary trees. If you grant me some lenience for my modeling, I will prove an O(1) amortized bound w.h.p., which I believe explains the power of the algorithms much better.
1 There is an unfortunate tendency of some TCS papers to use "worst case" when they really mean deterministic. I am much happier with the convention that worst case is opposite of amortized, at least when your paper has any connection to data structures.Formally, I will prove the following, rather trivial statement:
Let T≥clg n, for a large enough constant c. Any T operations in chaining hashtables only touch O(T) memory w.h.p.Fix the hash codes of the T elements, and define our "bin" to consist of these ≤T distinct hash codes. All other elements are still totally random, and we expect μ≤Tn/b=Θ(lg n) to fall into the bin. If μ≤Z/(2e), the Chernoff bound is eZ-μ/(μ/Z)Z ≤ 2-μ = high probability.
But does this actually mean that chaining has O(1) amortized running time? Formally, no: if I repeat a single query T times, the running time will be T times the running time of that query, i.e. a geometric random variable with no good concentration. Here is where I invoke a bit of lenience in my modeling: in practice, it is ridiculous to worry about repeating one of the last O(lg n) operations! The memory used by these recent updates will be fresh in the first level of cache, making a repetition cost essentially zero. (One may formally say that chaining has amortized O(1) running time w.h.p. in the external memory model with a cache of size Ω(lg n).)
A pretty way to understand the amortized bound is as a "buffer size" guarantee. The most demanding applications of hashtables are in analyzing a continuous stream of data, when operations need to be super-fast to keep up with the line speed. In such application, if the design is at all sensible, there will be a buffer between the network interface and our CPU. The goal is not necessarily to take O(1) time for every single operation, but to keep the buffer small. Our proof says that the buffer will not grow to more than T=O(lg n) w.h.p., if you can afford the average time/operation.
For linear probing, we can instead show:
Let T=Ω(lg3n). Any T operations in chaining hashtables only touch O(T) memory w.h.p.Remember from last time that we analyzed linear probing by building a binary tree over the array, and bounding the number of nodes that become dangerous (two-thirds full).
Let μ be the number of keys we expect under some node. First of all, if μ≫lg n, we do not need to worry about the node: it doesn't become dangerous w.h.p. Otherwise, we showed that the node becomes dangerous with probability O(1/μ2); if it does, we will pay a cost of μ.
Looking at T elements, I am dealing with ≤T nodes on each level, and I expect O(T/μ2) nodes to be dangerous. As long as T/μ2 ≥ clg n, Chernoff tells me that only O(T/μ2) nodes are dangerous w.h.p. Since we only deal with μ=O(lg n), I needed to set T=Ω(lg3n). With this bound, the number of memory locations accessed by the T operations is Σμ=2^i O(T/μ2)·μ = O(T) w.h.p.
I end with a question to my knowledgeable readers. By being more careful, I can prove T=Ω(lg1+εn) suffices for linear probing. Is it possible to prove T=Ω(lg n), as in chaining? (Perhaps I'm missing something obvious.)
Wednesday, January 27, 2010
Basic Hashtables
To understand the state of the art in hash tables, you must understand the holy trinity of the area: chaining, linear probing, and cuckoo hashing. Chaining is the one that amateurs know, and shows up frequently in code. Linear probing is what you use when performance really matters. And cuckoo hashing is the theoretician's darling, providing the playground for a constant stream of papers.
Here is a basic description of the three hash tables, if you don't know them. There are, of course, many variations.
Chaining. It is trivial to argue that the expected running time of insertions
and deletions is constant. Focus on some element q. For i≠q, let Xi be the indicator that h(i)=h(q). Then, the time it takes to insert or query q is O(1 + ΣXi).
Therefore, the expected time is bounded by E[ΣXi] = ΣE[Xi] = n/b = O(1), since h(x)=h(i) only happens with probability 1/b.
What we have just argued is that the expected number of elements that collide with x is O(1). Another way to state this is that the variance of a bin's size is O(1), a fact that we proved last time. To see this connection, let Bi be the number of elements in bin i. Observe that:
Perfect hashing. A very cool consequence of this variance analysis is the well-known dictionary of [Fredman, Komlós, Szemerédi FOCS'82]. Their idea was to construct a static dictionary using randomization, but then have the query be completely deterministic. (Later work has focused on obtaining deterministic queries even in dynamic dictionaries, as in cuckoo hashing, and on completely eliminating randomness.)
The basic idea is that, if we had space 2n2, perfect static dictionaries would be trivial. Indeed, the expected number of collisions is n2 / b = 1/2, so, by Markov, the hash function is collision-free with probability at least 1/2. For the construction, we can simply generate hash functions until we see a perfect one (a constant number of iterations, in expectation).
To bring the space down to O(n), remember that our variance analysis showed E[Σ(Bi)2] = O(n). Thus, instead of storing the items mapping to A[i] as a linked list, we should store a mini-hashtable of quadratic size inside each A[i]. These mini-tables provide perfect hashing, but their total size is just linear!
Linear probing. The relevance of moments to linear probing was only recognized in a recent breakthrough paper [Pagh, Pagh, Ruzic STOC'07]. I will show the analysis for b=3n to ease notation; it is easy to extend to any load.
In true data-structures style, we consider a perfect binary tree spanning the array A[1..b]. A node on level k has 2k array positions under it, and (1/3)·2k items were originally hashed to them in expectation. (Here I am counting the original location h(x) of x, not where x really appears, which may be h(x)+1, h(x)+2, ...). Call the node "dangerous" if at least (2/3)·2k elements hashed to it.
Now say that we are dealing with element q (a query or an update). We must bound the contiguous run of elements that contain the position h(q). The key observation is that, if this run contains between 2k and 2k+1 elements, either the ancestor of h(q) at level k-2 is dangerous, or one of its siblings in an O(1) neighborhood is dangerous.
Let's say this run goes from A[i] to A[j], i≤h(q)≤j. The interval [i,j] is spanned by 4—9 nodes on level k-2. Assume for contradiction that none are dangerous. The first node, which is not completely contained in the interval, contributes less than (2/3)·2k-2 elements to the run (it the most extreme case, this many elements hashed to the last location of that node). But the next nodes all have more than 2k-2/3 free locations in their subtree, so 2 more nodes absorb all excess elements. Thus, the run cannot go on for 4 nodes, contradiction.
Now, the expected running time of an operation is clearly:
The rest is a simple balls-in-bins analysis: we want the probability that a bin, of expected size μ=2k-2/3, actually contains 2μ elements. Last time, we showed that Chebyshev bounds this probability by O(1/μ). Unfortunately, this is not enough, since Σk 2k·O(1/2k-2) = O(lg n).
However, if we go to the 4th moment, we obtain a probability bound of O(1/μ2). In this case, the running time is Σk2k·O(1/22(k-2)) = Σ O(2-k) = O(1). So the 4th moment is enough to make this series decay geometrically.
Here is a basic description of the three hash tables, if you don't know them. There are, of course, many variations.
- chaining
- Each item x is hashed to one of b bins, where b=Ω(n). Each bin is stored as a linked list, with pointers to the head of each list stored in an array A[1..b]. In practice, you would store the head of each list in A[i], to save a pointer and a cache miss.
- linear probing
- We hold an array A[1..b] of records, where b ≥ (1+ε)n. When inserting x, we try to place it at A[h(x)]; if that location is empty, try A[h(x)+1], A[h(x)+2], ..., until you find an empty location. This addresses the main performance issues of chaining: there are no cache misses (we walk a contiguous region, not a linked list), and the space is better (no pointers). But, intuitively, it demands much more robustness from the hash function: now some elements hashing to location k can interfere negatively with elements hashing to a close k'.
- cuckoo hashing
- We hold two arrays A[1..b] and B[1..b] and use two hash functions, h and g. When x arrives, we try to put it at A[h(x)]. If that location already contains y, try to move y to B[g(y)]. If that location already contains z, try to move z to A[h(z)], and so on until you find a free spot. Observe that the query for x is worst-case constant time: just look for x in A[h(x)] and B[g(x)]!
Chaining. It is trivial to argue that the expected running time of insertions
and deletions is constant. Focus on some element q. For i≠q, let Xi be the indicator that h(i)=h(q). Then, the time it takes to insert or query q is O(1 + ΣXi).
Therefore, the expected time is bounded by E[ΣXi] = ΣE[Xi] = n/b = O(1), since h(x)=h(i) only happens with probability 1/b.
What we have just argued is that the expected number of elements that collide with x is O(1). Another way to state this is that the variance of a bin's size is O(1), a fact that we proved last time. To see this connection, let Bi be the number of elements in bin i. Observe that:
E[Σ(Bi)2] = n + E[#colliding pairs] = n + n · E[#elements colliding with x] = n + n2/bBy uniformity of the hash function, E[(Bi)2] = n/b + n2/b2. We have obtained the variance: Var[Bi] = E[(Bi)2] - E[Bi]2 = n/b.
Perfect hashing. A very cool consequence of this variance analysis is the well-known dictionary of [Fredman, Komlós, Szemerédi FOCS'82]. Their idea was to construct a static dictionary using randomization, but then have the query be completely deterministic. (Later work has focused on obtaining deterministic queries even in dynamic dictionaries, as in cuckoo hashing, and on completely eliminating randomness.)
The basic idea is that, if we had space 2n2, perfect static dictionaries would be trivial. Indeed, the expected number of collisions is n2 / b = 1/2, so, by Markov, the hash function is collision-free with probability at least 1/2. For the construction, we can simply generate hash functions until we see a perfect one (a constant number of iterations, in expectation).
To bring the space down to O(n), remember that our variance analysis showed E[Σ(Bi)2] = O(n). Thus, instead of storing the items mapping to A[i] as a linked list, we should store a mini-hashtable of quadratic size inside each A[i]. These mini-tables provide perfect hashing, but their total size is just linear!
Linear probing. The relevance of moments to linear probing was only recognized in a recent breakthrough paper [Pagh, Pagh, Ruzic STOC'07]. I will show the analysis for b=3n to ease notation; it is easy to extend to any load.
In true data-structures style, we consider a perfect binary tree spanning the array A[1..b]. A node on level k has 2k array positions under it, and (1/3)·2k items were originally hashed to them in expectation. (Here I am counting the original location h(x) of x, not where x really appears, which may be h(x)+1, h(x)+2, ...). Call the node "dangerous" if at least (2/3)·2k elements hashed to it.
Now say that we are dealing with element q (a query or an update). We must bound the contiguous run of elements that contain the position h(q). The key observation is that, if this run contains between 2k and 2k+1 elements, either the ancestor of h(q) at level k-2 is dangerous, or one of its siblings in an O(1) neighborhood is dangerous.
Let's say this run goes from A[i] to A[j], i≤h(q)≤j. The interval [i,j] is spanned by 4—9 nodes on level k-2. Assume for contradiction that none are dangerous. The first node, which is not completely contained in the interval, contributes less than (2/3)·2k-2 elements to the run (it the most extreme case, this many elements hashed to the last location of that node). But the next nodes all have more than 2k-2/3 free locations in their subtree, so 2 more nodes absorb all excess elements. Thus, the run cannot go on for 4 nodes, contradiction.
Now, the expected running time of an operation is clearly:
Σk O(2k)·Pr[h(q) is in a run of 2k to 2k+1 elements].As argued above, this probability is at most O(1) times the probability that a designated node at level k-2 is dangerous.
The rest is a simple balls-in-bins analysis: we want the probability that a bin, of expected size μ=2k-2/3, actually contains 2μ elements. Last time, we showed that Chebyshev bounds this probability by O(1/μ). Unfortunately, this is not enough, since Σk 2k·O(1/2k-2) = O(lg n).
However, if we go to the 4th moment, we obtain a probability bound of O(1/μ2). In this case, the running time is Σk2k·O(1/22(k-2)) = Σ O(2-k) = O(1). So the 4th moment is enough to make this series decay geometrically.
Tuesday, January 26, 2010
Moments
This post is a fairly basic review of common probability notions. Things will get more interesting in future posts. Somebody who wants to do TCS but has not studied probability yet can read this post carefully and reach about the same level of formal training that I've had :)
Say we distribute n items into b bins randomly. Fixing our attention on one bin (e.g. the first), how can be bound the number of items landing there?
The expected number of items is n/b. Thus, by the Markov bound, we get:
Variance. To strengthen the bound, we may look at the variance and apply the Chebyshev bound. Let X be the number of elements in the first bin. Also let μ=E[X]=n/b. The variance of X is defined as E[(X-μ)2], and this is exactly what we need to compute for Chebyshev.
How can we compute the variance? We let Xi be the indicator for whether the i-th item falls in our bin (indicator means the variable is 1 if the event happens, and 1 otherwise). Then, X=X1+...+Xn.
Since we are interested in X-μ, not X, it is more convenient to define Yi = Xi-(1/b). With this definition, X-μ=Y1+...+Yn. Observe that E[Yi] = 0.
We can not break up the variance:
We have found the variance to be E[(X-μ)2]=O(n/b)=O(μ). Then:
Fourth moment. To strengthen the variance bound, one most commonly looks at the 4th moment. To get a feeling for it, let's see how we can bound the 4th moment in the balls and bins case:
To bound the bin size, we can now apply Markov on the fourth moment:
Chernoff. The next step to improving our bounds is to go to the Chernoff bound. This bound has many forms, in particular two rather different instantiations for additive and relative error.
Let me quote an uncommon, but nifty version of the theorem:
If we have been interested in showing that the bin gets at least Z=μ/2 elements, the second part of the theorem gives a probability bound of e-μ/2 2μ/2 ≈ 1 / 1.17μ. Note how the two terms of the bound trade places: eZ-μ is pushing the probability down in the second case, while (μ/Z)Z is making sure it is small in the first case.
The proof of Chernoff is a bit technical, but conceptually easy. As before, we define Yi = Xi - E[Xi], so that X-μ=ΣYi. Instead of looking at E[(X-μ)k], we will not look at E[αX-μ] (where α>1 is a parameter than can be optimized at the end). This quantity is easy to compute since E[αΣYi] = E[Π αYi] = Π E[αYi]. At the end, we can just apply Markov on the positive variable αX-μ.
High probability. In TCS, we are passionate about bounds that hold "with high probability" (w.h.p.), which means probability 1 - 1/nc, for any constant c. For instance,
Since we are usually happy with whp bounds, one often hears that Chernoff is morally equivalent to O(lg n)-moments. Indeed, such a moment will give us a bound of the form 1/μO(lg n), which is high probability even in the hardest case when μ is a constant.
The paper of [Schmidt, Siegel, Srinivasan SODA'93] is often cited for this. Their Theorem 5 shows that you can get the same bounds as Chernoff (up to constants) if you look at a high enough moment.
Say we distribute n items into b bins randomly. Fixing our attention on one bin (e.g. the first), how can be bound the number of items landing there?
The expected number of items is n/b. Thus, by the Markov bound, we get:
Pr[bin contains ≥ 2n/b items] ≤ 1/2
How can we compute the variance? We let Xi be the indicator for whether the i-th item falls in our bin (indicator means the variable is 1 if the event happens, and 1 otherwise). Then, X=X1+...+Xn.
Since we are interested in X-μ, not X, it is more convenient to define Yi = Xi-(1/b). With this definition, X-μ=Y1+...+Yn. Observe that E[Yi] = 0.
We can not break up the variance:
Var[X] = E[(X-μ)2] = E[( ΣYi )2] = Σ E[YiYj]We are down to analyzing E[YiYj], which is simple. If i≠j, Yi and Yj are independent random variables. Thus, the expectation commutes with the product:
E[YiYj] = E[Yi] E[Yj] = 0In the case i=j, we use brute force calculation. Yi=-1/b with probability 1-(1/b), and equals 1-(1/b) with probability 1/b. Thus, E[(Yi)2] = O(1/b).
We have found the variance to be E[(X-μ)2]=O(n/b)=O(μ). Then:
Pr[X ≥ 2n/b] = Pr[X-μ ≥ μ] ≤ Pr[(X-μ)2 ≥ μ2] ≤ O(μ) / μ2 = O(1/μ)Observe that the Chebyshev bound is nothing more than Markov on the variable (X-μ)2.
Third moment. If stronger bounds are required, we can try to look at higher moments, E[(X-μ)k]. Unfortunately, moving to the 3rd moment (or any other odd moment) does not really help: the variable (X-μ)3 is no longer positive, so Markov cannot apply.
One way to fix this is to look at the absolute third moment: E[|X-μ|3]. It is no longer easy to compute this moment, since we cannot break up |ΣYi|3 into components, due to the absolute value. Thus, we do not commonly use absolute moments.
However, I have come across absolute moments once, in the following interesting application. The central limit theorem states that the average of N i.i.d. variables tends to the normal distribution as N→∞. The Berry-Esseen theorem quantifies this phenomenon: it gives a fairly strong bound on the speed of the convergence, assuming the third absolute moment of the summands is bounded.
One way to fix this is to look at the absolute third moment: E[|X-μ|3]. It is no longer easy to compute this moment, since we cannot break up |ΣYi|3 into components, due to the absolute value. Thus, we do not commonly use absolute moments.
However, I have come across absolute moments once, in the following interesting application. The central limit theorem states that the average of N i.i.d. variables tends to the normal distribution as N→∞. The Berry-Esseen theorem quantifies this phenomenon: it gives a fairly strong bound on the speed of the convergence, assuming the third absolute moment of the summands is bounded.
Fourth moment. To strengthen the variance bound, one most commonly looks at the 4th moment. To get a feeling for it, let's see how we can bound the 4th moment in the balls and bins case:
E[(X-μ)4] = E[( ΣYi )4] = Σijkl E[ YiYjYkYl ]We can understand the terms generated by an (i,j,k,l) tuple by case analysis:
- If one of the elements appears exactly once, the term is zero. For instance, let's say i∉ {j,k,l}. Then Yi is independent of the rest, so the expectation commutes with product: E[YiYjYkYl] = E[Yi] E[YjYkYl] = 0.
- If all elements are equal (i=j=k=l), E[(Yi)4] = O(1/b).
- If the tuple consists of two equal pairs, for instance (i,i,j,j), we have E[(Yi)2 (Yj)2] = E[(Yi)2] E[(Yj)2] = O(1/b2).
To bound the bin size, we can now apply Markov on the fourth moment:
Pr[X ≥ 2n/b] = Pr[X-μ ≥ μ] ≤ Pr[(X-μ)4 ≥ μ4] ≤ O(μ2) / μ4 = O(1/μ2)Thus, our bounds have improved from 1/2 for Markov, to O(1/μ) for Chebyshev, and to O(1/μ2) for the 4th moment. Going to the 6th, 8th, etc yields the predictable improvement.
Chernoff. The next step to improving our bounds is to go to the Chernoff bound. This bound has many forms, in particular two rather different instantiations for additive and relative error.
Let me quote an uncommon, but nifty version of the theorem:
Let X1, ..., Xn be independent random variables bounded in [0,1]. Let X=ΣXi and μ=E[X].
If Z≥μ, then Pr[X≥Z] ≤ eZ-μ (μ/Z)Z.
If Z≤μ, then Pr[X≤Z] ≤ eZ-μ (μ/Z)Z.In our case, we are interested in Z=2μ. Thus, the upper bound on the probability is eμ / 22μ ≈ 1 / 1.47μ. We have obtained an exponential bound, instead of the polynomial bound possible by constant moments.
If we have been interested in showing that the bin gets at least Z=μ/2 elements, the second part of the theorem gives a probability bound of e-μ/2 2μ/2 ≈ 1 / 1.17μ. Note how the two terms of the bound trade places: eZ-μ is pushing the probability down in the second case, while (μ/Z)Z is making sure it is small in the first case.
The proof of Chernoff is a bit technical, but conceptually easy. As before, we define Yi = Xi - E[Xi], so that X-μ=ΣYi. Instead of looking at E[(X-μ)k], we will not look at E[αX-μ] (where α>1 is a parameter than can be optimized at the end). This quantity is easy to compute since E[αΣYi] = E[Π αYi] = Π E[αYi]. At the end, we can just apply Markov on the positive variable αX-μ.
High probability. In TCS, we are passionate about bounds that hold "with high probability" (w.h.p.), which means probability 1 - 1/nc, for any constant c. For instance,
Algorithm A runs in O(n) time w.h.p.formally means the following:
There exists a function f(.) such that, if you choose any constant c, I can prove that algorithm A runs in time f(c)·n with probability 1 - 1/nc.While such bounds may seem weird at first, they do make a lot of sense: think of applying some randomized procedure a polynomial number of times. Also, these bounds make a lot more sense when dealing with many experiments over huge data sets (the essence of Computer Science) than adopting the convention from statistics, which asks for bounds that hold with 95% probability.
Since we are usually happy with whp bounds, one often hears that Chernoff is morally equivalent to O(lg n)-moments. Indeed, such a moment will give us a bound of the form 1/μO(lg n), which is high probability even in the hardest case when μ is a constant.
The paper of [Schmidt, Siegel, Srinivasan SODA'93] is often cited for this. Their Theorem 5 shows that you can get the same bounds as Chernoff (up to constants) if you look at a high enough moment.
Thursday, January 21, 2010
Applications
This is the time when many young people are fretting about their applications, be they for undergrad admission, PhD admission, or academic jobs. (At the same time, marginally older people are happy to be done with recommendation letters.)
First of all, I wanted to suggest that you channel the energy (or, should I say, agitation) of this moment into positive directions. My interview spring was also when I came up with some pretty neat ideas and wrote 4 FOCS papers.
Second of all, I wanted to share an anecdote that I heard during my job hunt, which may or may not help. As the story goes, a department chair comes back after the break and finds a couple of hundred applications sitting on his desk. He looks at the pile, shakes his head, and promptly commits half of them to the recycle bin. He then announces that, "This university does not need unlucky people."
If you doubt that this could be true, let me offer statistical evidence from my wife's hospital: on her year, the doctors that got jobs were Maria, Miriam, Mariam, and Milos. (Evidently, the secretary had sorted the pile before putting it on the chair's desk.)
Amusingly, their workplace also offers the best illustration of a hash function collision that I have yet seen. They have three Romanian doctors which go by Mira, Mira, and Mera (hash codes for Mirabela, Miriam, and Merima -- all exceedingly rare names in Romania).