We all know the number guessing game. I think of an integer between 1 and n, and you try to guess it by comparison queries, "is it larger than x?". Binary search takes ceiling(log2 n) queries, which is of course optimal.
But what if I think of a rational number a/b , with 0<a<b<n? Can you still guess it with a few comparison queries? Take a few seconds to show that you can guess it with 2log2 n + O(1) queries, and that's optimal. (It's a 1-line proof.)
x
x
x
x
x
x
This space intentionally left blank.
x
x
x
x
x
x
Two fractions with denominators up to n cannot be closer than 1/n2. Thus, you binary search for k such that the number is in the interval [k/n2 , (k+1)/n2). This interval contains a single fraction, so you can just go through all fractions and find the one inside. On the lower-bound side, there are on the order of n2 fractions, so it takes at least 2log2 n - O(1) queries with binary output.
The moral of the story is, of course: be careful about the difference between actual running time and query complexity. But now let us show that you can actually find the unique fraction in the small interval with running time O(lg n). There are several papers doing this, including:
- Christos Papadimitriou, Efficient search for rationals, IPL 1979.
- Steven P. Reiss, Efficient search for rationals, IPL 1979
- Stephen Kwek and Kurt Mehlhorn, Optimal Search for Rationals, IPL 2003.
The really cool property of irreducible fractions is that if a/b and c/d are consecutive in some Farey sequence, then the "mediant" (a+b)/(c+d) is the first fraction that appears between them in a higher-order sequence. For example, the first fraction to appear between 1/2 and 2/3 will be 3/5.
With this property, we can construct the Stern-Brocot tree, which is an infinite tree exploring all fractions less than 1. The following picture from Wikipedia should explain everything:
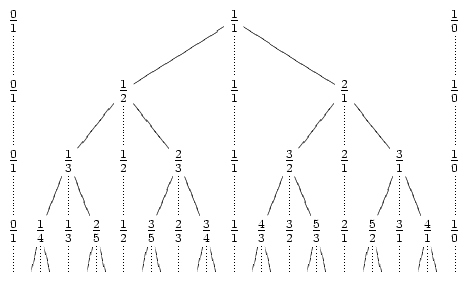 The intuitive algorithm is to go down this tree, looking for our fraction. Unfortunately, fractions with small denominators can appear very deep in the tree -- for example, 1/n is at depth n-1. Thus, we get O(n) time.
The intuitive algorithm is to go down this tree, looking for our fraction. Unfortunately, fractions with small denominators can appear very deep in the tree -- for example, 1/n is at depth n-1. Thus, we get O(n) time.To improve this, we first show that the number of "turns" of the exploration is at most O(lg n). By turn, I mean switching from a going down on left children, to going down on right children (note that the 1/n example above had zero turns). Looking at the tree, it is easy to see that a turn essentially doubles denominators, so the property is easy to show.
Now we have to explore the straight descents efficiently. Let's say the fraction falls between a/b and c/d, and we take t steps to the left. This will land us at precisely (ta+b)/(tc+d). We can solve this equation for t, and find the minimum value which makes the fraction less than the target interval. Thus, we can calculate the number of consecutive left steps in constant time.
If we're too lazy to solve the equation, we can binary-search for t. Here we use galopping binary search, i.e. we take time O(lg t) to guess the unknown t.
Surprisingly, this will not give O(lg2n) time in total, but still takes O(lg n) time. This follows because the sum of the lg t values traces the number of times the denominator doubles, and it can only double O(lg n) times.
Overall, we have query complexity, Farey sequences, doubling arguments, galopping binary search, and summing up logarithms. This probably makes very nice material for an undergraduate "Math for CS" course.
(As a person who has never taken, nor taught such a course, I of course feel entitled to have opinions about it.)

 Web views/day on average
Web views/day on average