This is the second post about "Changing Base without Losing Space." The main result of the paper is, if I am allowed to say it, rather amazing:
On a binary computer, you can represent a vector of N decimal digits using ⌈N·log210⌉ bits, and support reading/writing any digit in constant time.
Of course, this works for any alphabet Σ; decimal digits are just an example.
Unlike the prefix-free coding from last time, this may never find a practical application. However, one can hardly imagine a more fundamental problem than representing a vector on a binary computer --- this statement that could have been discovered in 1950 or in 2050 :) Somebody characterized our paper as "required reading for computer scientists." (In fact, if you teach Math-for-CS courses, I would certainly encourage you to teach this kind of result for its entertainment value.)
To understand the solution, let's think back of the table for prefix-free coding from last time:
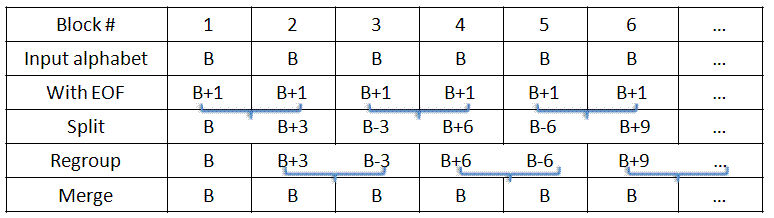
Here is the reasoning process behind the first few operations:
- I have two symbols from alphabet B+1. I need an output alphabet of B, so let's split them into a letter from B, and whatever is left (in particular, a letter from B+3).
- I have a letter from B+3. Can I combine it with another letter to make something close to a power of 2? Yes, I should use a letter from alphabet B-3, since (B+3)(B-3) is close to B2.
- How can I get a letter from B-3? Take the next two input symbols, and split them into a letter from B-3, and whatever is left (in particular, a letter from B+6).
To generalize, let's assume we want to code something from an alphabet
X (not a power of two). We can store it in binary without loss of space, if we have another, unrelated, symbol to code (an
information carrier). In a picture:

If I want to output M bits (M≫lg X), I have to combine the symbol from X with a symbol from Y=⌊2M/X⌋. The loss of entropy will be lg(Y+1) - lg Y = O(1/Y), since the floor function could convert Y+0.9999 into Y.
Now I have to get a symbol from Y. This is possible if my information carrier came from some alphabet T≫Y. Then, I can break it into a symbol from Y, and one from Z=⌈T/Y⌉. Again, the entropy loss is lg Z - lg(Z-1)=O(1/Z), since the ceiling can convert Z-0.9999 into Z.
To balance the losses, set Y≈Z≈√T. That is, by having a large enough information carrier, I can make the loss negligible. In particular, if I apply the information carrier N times, I could set T≈N2, meaning that I only lose O(1/N) bits per application, and only a fraction of a bit overall! (This fraction of a bit will become one entire bit at the end, since I need to write the last symbol in binary.)
Thus, in principle, I could encode an array of digits by grouping them into blocks of O(lg N) digits (making T=the alphabet of a block be large enough). Then, I can iteratively use one block as the information carrier for the leftover of the previous block (the Z value from the previous block). The crucial observation is that, to decode block i, we only need to look at memory locations i (giving the Y component) and i+1 (giving the Z component). Thus, we have constant time access!
The one questionable feature of this scheme is that it requires O(N) precomputed constants, which is cheating. Indeed, the alphabets Y and Z change chaotically from one iteration to the next (the next Y is dictated by the previous Z, "filling it" to a power of two). There seems to be no pattern to these values, so I actually need to store them.
One can get away with just O(lg N) constants by applying the information carrier idea in a tree fashion. The alphabets will vary from level to level, but are identical on one level by symmetry. See the paper for complete details.
I will talk about my second STOC paper ("Towards Polynomial Lower Bounds for Dynamic Problems") after the conference.




 Web views/day on average
Web views/day on average