I am told the least this blog could do is to talk about my own results :) So here goes.
Next week at STOC, I am presenting "Changing Base without Losing Space," a joint paper with Mikkel Thorup and Yevgeniy Dodis. The paper and slides can be found here. The paper contains two results achieved by the same technique. Today, I will talk about the simpler one: online prefix-free codes.
The problem is to encode a vector of bits of variable length in a prefix-free way; that is, the decoder should be able to tell when the code ends. (Note on terminology: In information theory, this is called "universal coding"; prefix-free is about coding letters from a fixed alphabet, e.g. the Hamming code is prefix-free.)
Let N be the (variable) length of the bit vector. Here are some classic solutions (known as Elias codes):
- A code of 2N bits: after each data bit, append one bit that is 0 for end-of-file (EOF) or 1 if more data is coming;
- A code of N+2lg N bits: at the beginning of the message, write N by code 1; then write the bit vector.
- A code of N+lg N+2lglg N bits: at the beginning, write N by code 2; then write the bit vector.
- Recursing, one obtains the optimal size of N+lg N+lglg N+...+O(lg*N)

However, this is only secure if the input is prefix-free, or otherwise we are vulnerable to extension attacks:

This creates the need for online prefix-free codes: I want to encode a stream of data (in real time, with little buffering), whose length is unknown in advance. In this setting, the simplest solution using 2N bits still works, but the others don't, since they need to write N at the beginning. In fact, one can "rebalance" the 2N solution into an online code of size N+O(√N): append a bit after each block of size √N, wasting a partially-filled block at the end. Many people (ourselves included) believed this to be optimal for quite some time...
However, our paper presents an online code with ideal parameters: the size is N+lg N+O(lglg N), the memory is only O(lg N), and the encoding is real time (constant time per symbol). Since the solution is simple and practical, there is even reason to hope that it will become canonical in future standards!
So, how do we do it? I will describe the simplest version, which assumes the input comes in blocks of b bits and that b≫2lg N (quite reasonable for b=128 as in AES). Each block is a symbol from an alphabet of size B=2b. We can augment this alphabet with an EOF symbol; in principle, this should not cost much, since lg(B+1)≈lg B for large B. More precisely, N symbols from an alphabet of B+1 have entropy N·lg(B+1) = N·b+O(N/B) bits, so there's negligible loss if B≥N.
The problem, though, is to "change base without losing space": how can we change from base B+1 (not a power of two) into bits in real time? A picture is worth 1000 words:
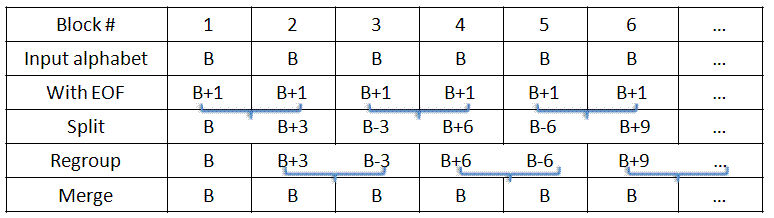
We can think of two continuously running processes that regroup two symbols into two symbols of different alphabets:
- Split: Two input symbols in alphabet B+1 are changed into two symbols in alphabets B-3i and B+3(i+1), for i=0,1,2,... This works as long as (B-3i)(B+3i+3) ≥ (B+1)2, which is always the case for n2 ≤ B/4 (hence the assumption b≫2lg N).
- Merge: Two input symbols in alphabet B-3i and B+3i are regrouped into two symbols in alphabet B, which can be written out in binary (b bits each). This is always possible, since (B-3i)(B+3i) ≤ B2

 Web views/day on average
Web views/day on average
5 comments:
This is very neat. I believe that if you exploit that there can be no two eofs in a row, you can replace the constant 3 by 2, and lose nothing in the splitting step.
Blog request: At some point you gave a talk about a combinatorial view of FFT. Any chance you could blog about that?
Rasmus, I like your idea of doing B and B+2 using no consecutive EOFs, but it will only work for the first double block. For the second, we will need (B-2)(B+4) = B^2 + 2B - 8 >= (B+1)^2 - 1 = B^2 - 2B, which is false.
Ironically, replacing 3 by 4 is actually better :).
Yevgeniy
Elias codes correspond to algorithms for the unbounded search problem, your code 2 corresponding to doubling search [Bentley and Yao, 1976], and any adaptive search algorithm yields a (compressed) prefix free code. Did you ponder what search algorithm corresponds to this new code, and what the cryptographic property of the code corresponds to for the search problem?
Thinking about it quickly, the search algorithm looks like a cache-friendly version of doubling search, in a cache-aware model, but I did not dig more into it, since you probably already explored this avenue?
Pa!
Jeremy
Jeremy: I didn't think about this. What would you hope to achieve? Doubling search is optimal, at least within constant factors...
Mihai: Doubling Search is optimal in the number of comparisons, but its access pattern is very cache unfriendly (you end up comparing one element in each block on long runs). The obvious theoretical answer is to replace it with some finger search in a B-Tree, but somehow, nobody I know does this in practice.
When I tried to optimize (experimentally) the running time (as opposed to the number of comparisons performed) of doubling search (in the context of intersection algorithms for sorted arrays), some cache-oblivious techniques did yield some improvements, but only for some of the biggest (intersection) instances. Had I considered cache-aware improvements, I think I would have used some blocking looking a bit like your larger alphabet.
Post a Comment